Tipp: a diák között a J és K billentyűkkel lehet lépkedni.
Letöltés
Párhuzamos és Grid rendszerek
(10. ea)
GPGPU
Szeberényi Imre
BME IIT
<szebi@iit.bme.hu>
Az ábrák egy része az NVIDIA oktató
anyagaiból és dokumentációiból származik.
M
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
EGYETEM 1782
2013.04.15.
-1-

Általános célú GPU
• A programozható vertex és fragment
shaderek beépítésével általános célú
eszközzé vált.
• Vektorprocesszor (SIMD), de pipeline
egységek is vannak benne (MISD).
• Jellemz en SIMD
• Programozás: CUDA, OpenCl, Cg, …
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-2-

Egy példa
NVIDIA Quadro FX5800 grafikus kártya
–
–
–
–
–
–
–
–
PCIe x16
240 CUDA mag
4 GB DDR3
78 GFlos double
933 Gflops single
189 W
300Millió háromszög / sec
NVIDIA CUDA
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-3-

SMEM
SMEM
SMEM
SMEM
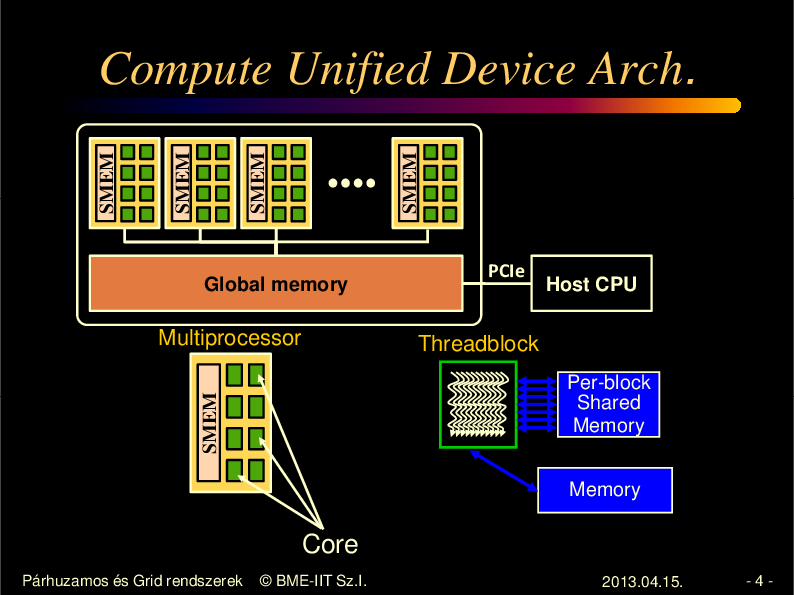
Compute Unified Device Arch.
Global memory
Multiprocessor
PCIe
Host CPU
Threadblock
SMEM
Per-block
Shared
Memory
Memory
Core
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-4-
CUDA modell
• Ún. thread modell (SIMT)
• A szálak ütemezésével nem kell a
programozónak foglalkozni.
• Elrejti a konkrét architektúrát
• Támogatja a heterogén feldolgozás
(CPU+GPU)
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-5-

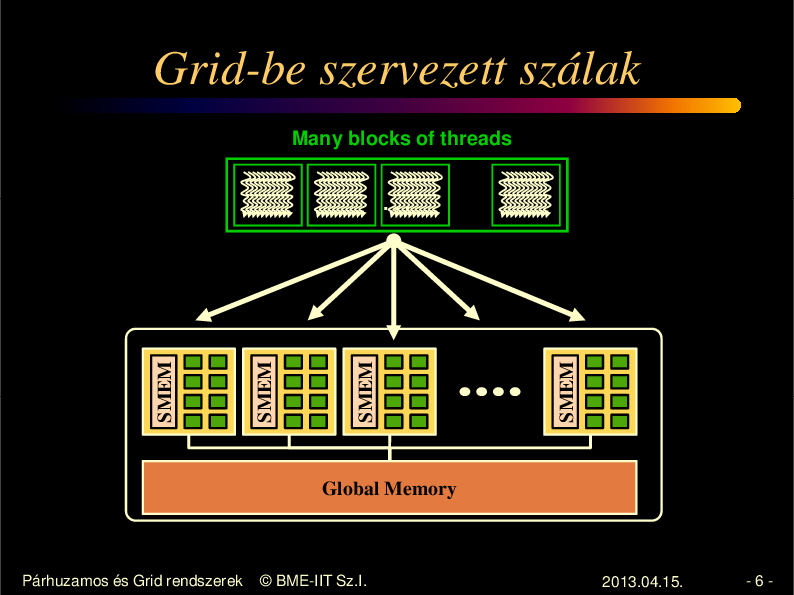
Grid-be szervezett szálak
Many blocks of threads
SMEM
SMEM
SMEM
SMEM
...
Global Memory
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-6-
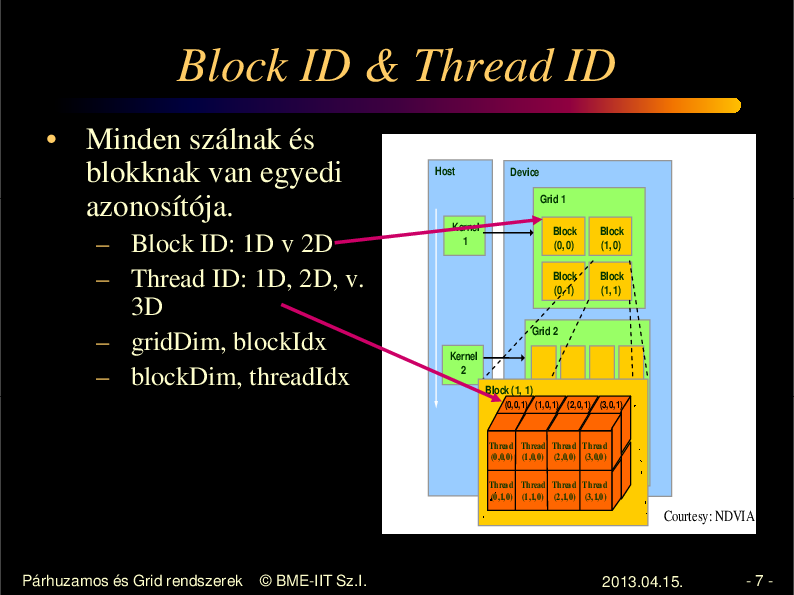
Block ID & Thread ID
• Minden szálnak és
blokknak van egyedi
azonosítója.
– Block ID: 1D v 2D
– Thread ID: 1D, 2D, v.
3D
– gridDim, blockIdx
– blockDim, threadIdx
Host
Device
Grid 1
Kernel
1
Block
(0, 0)
Block
(1, 0)
Block
(0, 1)
Block
(1, 1)
Grid 2
Kernel
2
Block (1, 1)
(0,0,1) (1,0,1) (2,0,1) (3,0,1)
Thread Thread Thread Thread
(0,0,0) (1,0,0) (2,0,0) (3,0,0)
Thread Thread Thread Thread
(0,1,0) (1,1,0) (2,1,0) (3,1,0)
Courtesy: NDVIA
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-7-
Szálak kommunikációja
• Szálak párhuzamosan futnak.
• Sorrendjük nem meghatározható
• Csak egy blokban lev szálak tudnak
kommunikálni egymással.
• A blokkok futási sorrendje nem
meghatározott.
• warp általában 32 szál
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
-8-

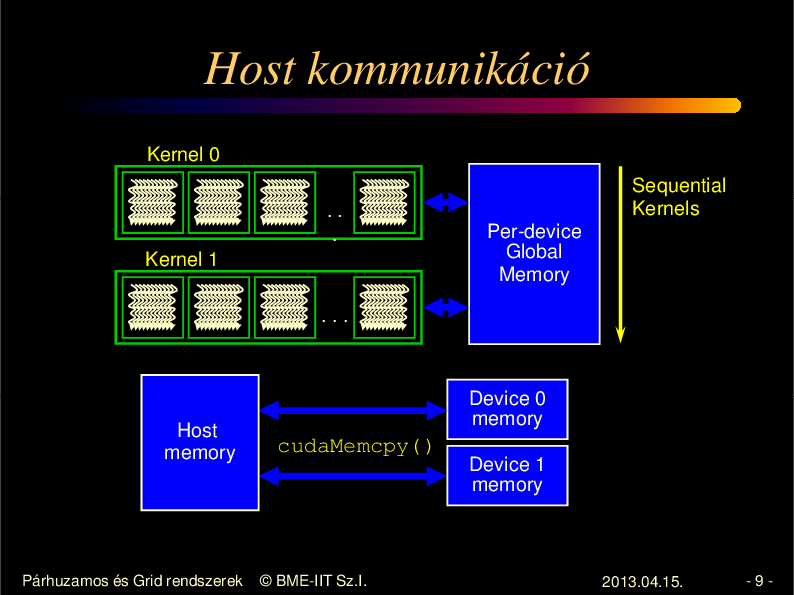
Host kommunikáció
Kernel 0
..
.
Kernel 1
Sequential
Kernels
Per-device
Global
Memory
...
Host
memory
Párhuzamos és Grid rendszerek
Device 0
memory
cudaMemcpy()
Device 1
memory
© BME-IIT Sz.I.
2013.04.15.
-9-
C nyelv kiegészítései
Függvény típus módósítói:
__global__ void my_kernel() { }
__device__ float my_device_func() { }
Változók típusmódosítói::
__constant__ float
my_constant_array[32];
__shared__
float
my_shared_array[32];
Beépített változók:
dim3 gridDim;
//
dim3 blockDim; //
dim3 blockIdx; //
dim3 threadIdx; //
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
Grid dimension
Block dimension
Block index
Thread index
2013.04.15.
- 10 -

C/C++ megkötések
•
•
•
•
•
Kernel kód csak a GPU memóriáját éri el
Nem lehet rekurzió
Nincs változó argumentumszám
Nincs static
Nincs dinamikus polimofrizmus
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2013.04.15.
- 11 -

Függvény deklaráció
Hol hajtódik
végre?
Honnan
hívható?
__device__ float DeviceFunc()
device
device
__global__ void
device
host
host
host
__host__
KernelFunc()
float HostFunc()
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 12 -

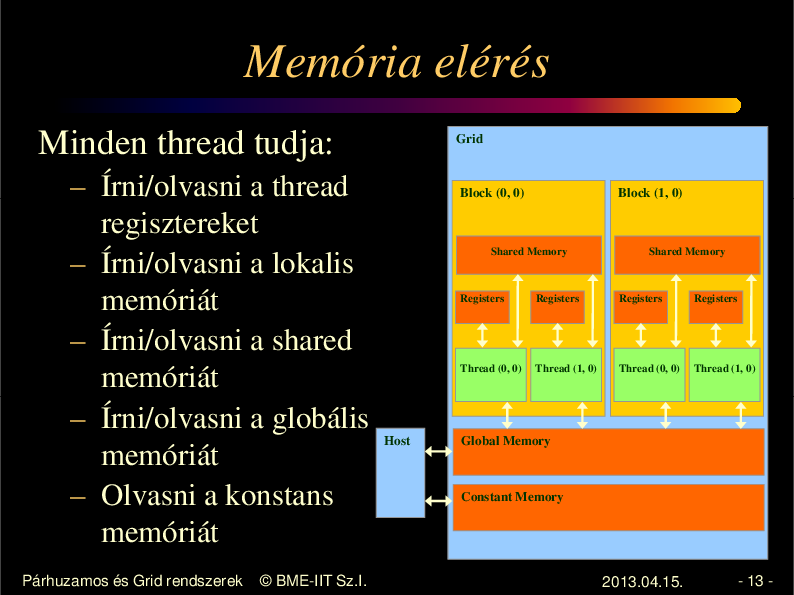
Memória elérés
Minden thread tudja:
– Írni/olvasni a thread
regisztereket
– Írni/olvasni a lokalis
memóriát
– Írni/olvasni a shared
memóriát
– Írni/olvasni a globális
memóriát
– Olvasni a konstans
memóriát
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
Grid
Block (0, 0)
Block (1, 0)
Shared Memory
Shared Memory
Registers
Registers
Registers
Thread (0, 0)
Host
Registers
Thread (1, 0)
Thread (0, 0)
Thread (1, 0)
Global Memory
Constant Memory
2013.04.15.
- 13 -
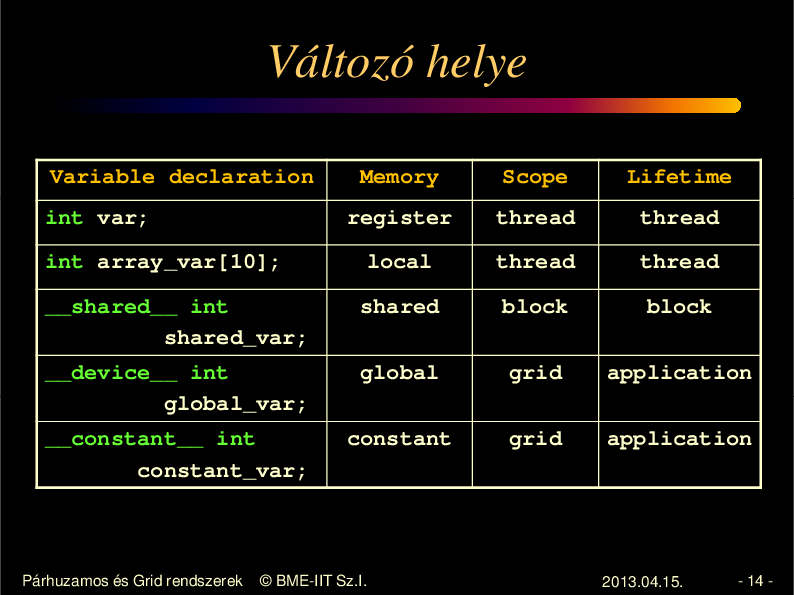
Változó helye
Variable declaration
Memory
Scope
Lifetime
register
thread
thread
int array_var[10];
local
thread
thread
__shared__ int
shared_var;
shared
block
block
__device__ int
global_var;
global
grid
application
__constant__ int
constant_var;
constant
grid
application
int var;
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 14 -
Elérés sebessége
Variable declaration
Penalty
register
int var;
Memory
int array_var[10];
local
__shared__ int
shared_var;
shared
1x
100x
1x
__device__ int
global_var;
global
100x
__constant__ int
constant_var;
constant
1x
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 15 -

Példa
• Vektor négyzetgyöke
• Bemenet/kimenet:
– input, output vektor
• Host program
• Device program
Threadblock
Per-block
Shared
Memory
Memory
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 16 -
Példa (sqrt #1)
// Device code
__global__ void sqrtVec(const double* in,
double* out, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
out[i] = sqrt(in[i]);
}
int main() {
....
sqrtVec<<<20, 256>>>(d_inp, d_res, SIZE);
....
}
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 17 -

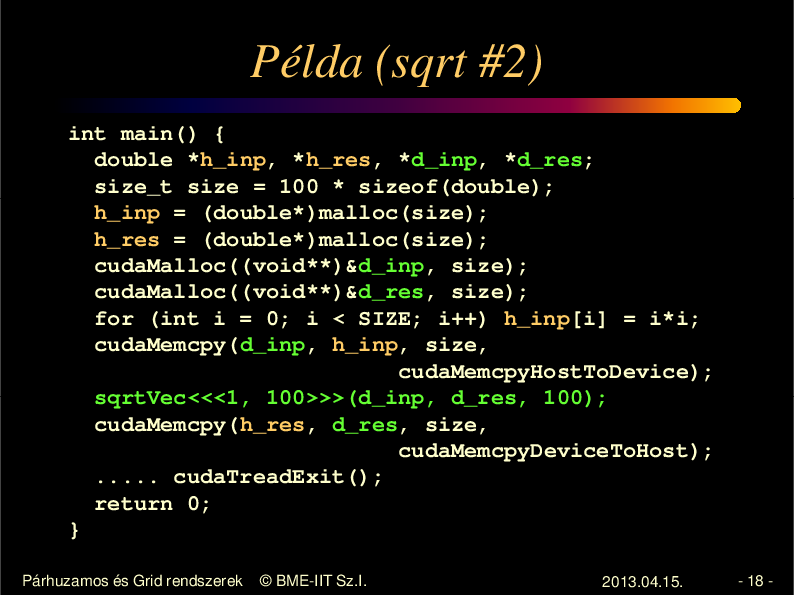
Példa (sqrt #2)
int main() {
double *h_inp, *h_res, *d_inp, *d_res;
size_t size = 100 * sizeof(double);
h_inp = (double*)malloc(size);
h_res = (double*)malloc(size);
cudaMalloc((void**)&d_inp, size);
cudaMalloc((void**)&d_res, size);
for (int i = 0; i < SIZE; i++) h_inp[i] = i*i;
cudaMemcpy(d_inp, h_inp, size,
cudaMemcpyHostToDevice);
sqrtVec<<<1, 100>>>(d_inp, d_res, 100);
cudaMemcpy(h_res, d_res, size,
cudaMemcpyDeviceToHost);
..... cudaTreadExit();
return 0;
}
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 18 -
Versenyhelyzet
threadId:0
threadId:1917
vector[0] = 5;
...
a = vector[0];
vector[0] = 1;
...
a = vector[0];
Mi az a változó értéke a 0. ill. 191. szálban ?
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 19 -

Atomi m velet
atomic{Add, Sub, Exch, Min, Max, Inc,
Dec, CAS, And, Or, Xor}
CAS:
int compare_and_swap(int* register,
int oldval, int newval){
int old_reg_val = *register;
if(old_reg_val == oldval)
*register = newval;
return old_reg_val;
}
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 20 -

Szinkronizációs veszély
__global__
void global_max(int* values, int*
gl_max){
int i = threadIdx.x
+ blockDim.x * blockIdx.x;
int val = values[i];
atomicMax(gl_max,val);
}
A gyakori közös memória hozzáférés miatt
a szálak elakadnak, szinkronozódnak.
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 21 -

Kicsit jobb max. keresés
__global__
void global_max(int* values, int* max,
int *regional_maxes, int num_regions)
{
int i = threadIdx.x
+ blockDim.x * blockIdx.x;
int val = values[i];
int region = i % num_regions;
if(atomicMax(®_max[region],val) <
val){
atomicMax(max,val);
}
}
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 22 -

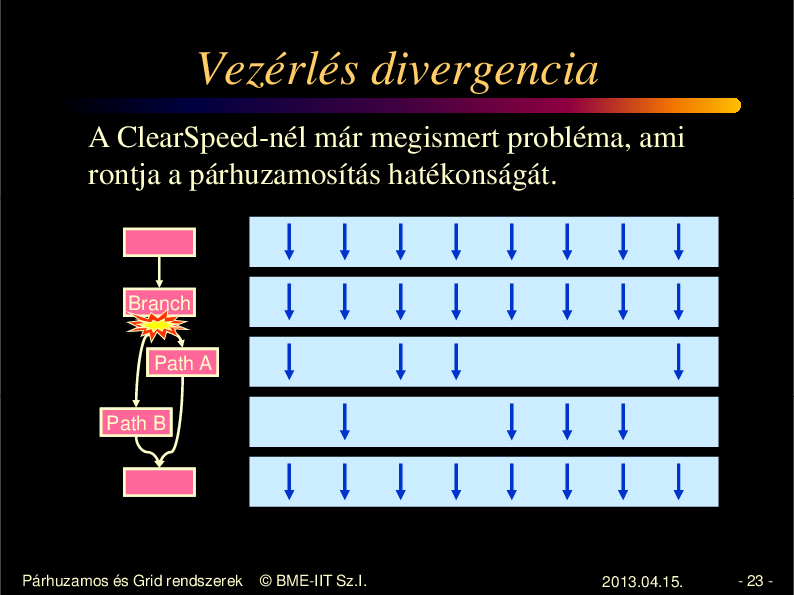
Vezérlés divergencia
A ClearSpeed-nél már megismert probléma, ami
rontja a párhuzamosítás hatékonságát.
Branch
Path A
Path B
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
2013.04.15.
- 23 -