Tipp: a diák között a J és K billentyűkkel lehet lépkedni.
Letöltés
Párhuzamos és Grid rendszerek
(10. ea)
egy vektorprocesszor
Szeberényi Imre
BME IIT
<szebi@iit.bme.hu>
M
Grir és OO labor © BME-IIT Sz.I.
EGYETEM 1782
2013.04.15.
-1-

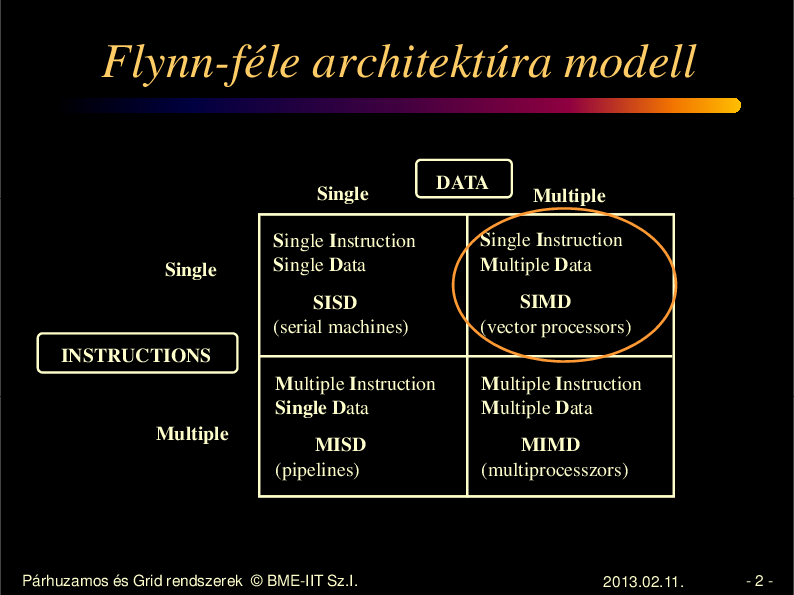
Flynn-féle architektúra modell
Single
DATA
Multiple
Single Instruction
Multiple Data
SISD
(serial machines)
SIMD
(vector processors)
Multiple Instruction
Single D
Data
Single
Single Instruction
Single Data
Multiple Instruction
Multiple D
M
Data
MISD
(pipelines)
MIMD
(multiprocesszors)
INSTRUCTIONS
Multiple
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2013.02.11.
-2-
ClearSpeed gyorsító kártya
• 2006: Tokyo Institute of Technology's
TSUBAME Supercomputer 47.38 TFLOPS
• ClearSpeed e710 kártya
–
–
–
–
–
Gyorsítókártya (PCIe x8)
2 db 96 magos processzor
2 x 8 GB DRR2, 2x128K SRAM
96 Gflops
24 W
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-3-

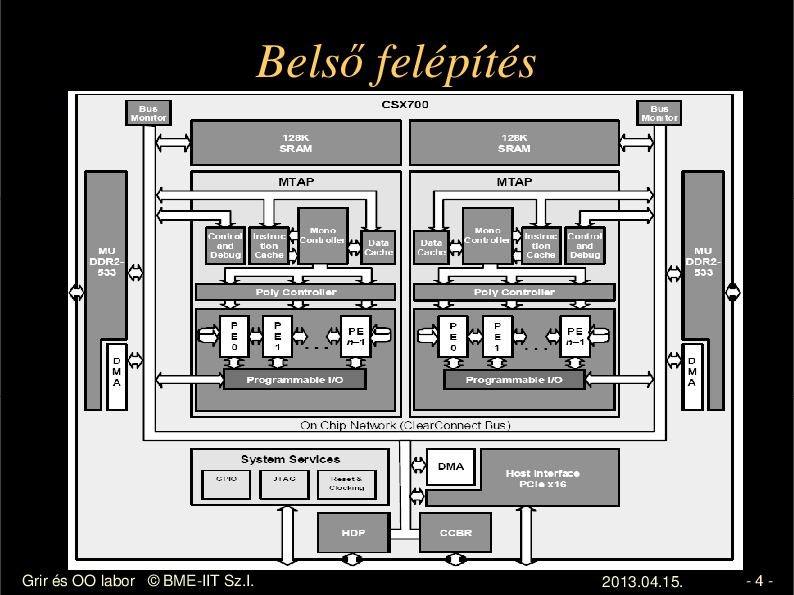
Bels felépítés
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-4-
Multi-threaded Array Processor
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-5-
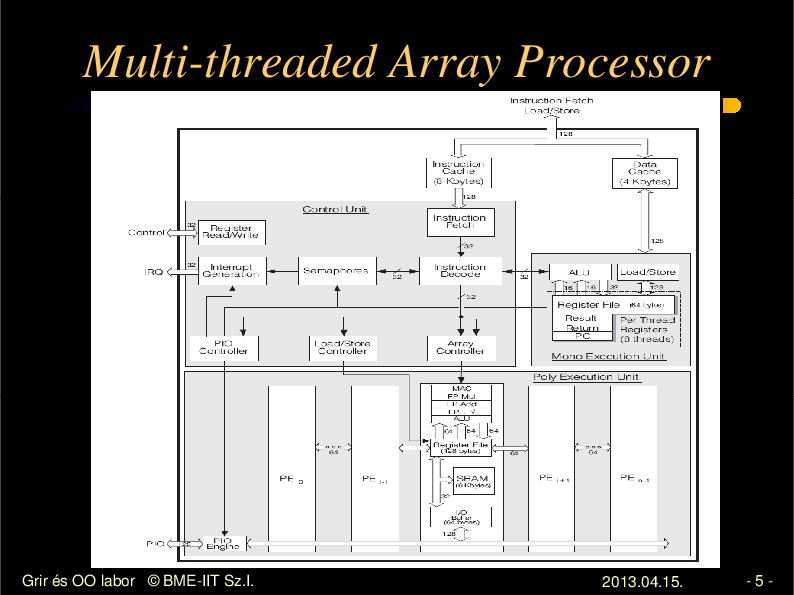
MTAP
• Control unit
– fetch, decode, -> mono, v. poly
– semaphore
• Poly controller
• Execution units
– 1 db mono
– 96 db poly
• Cache
• I/O
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-6-

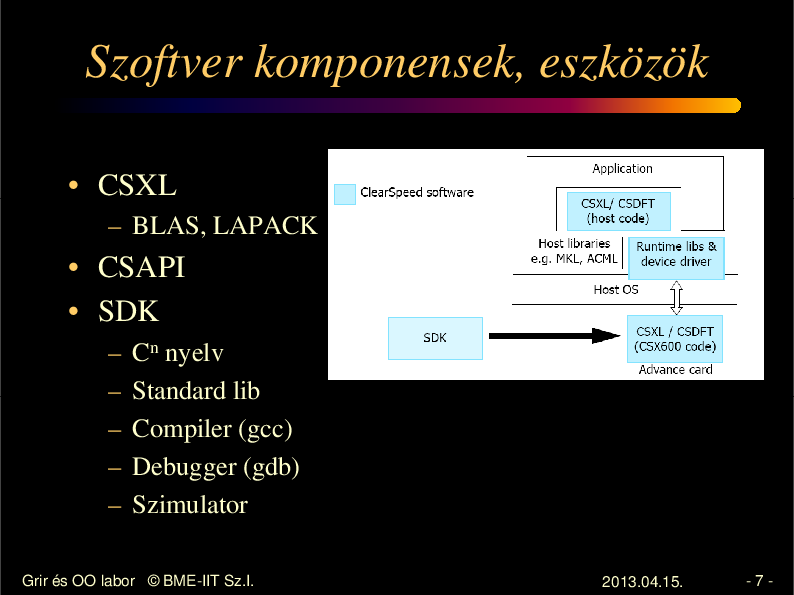
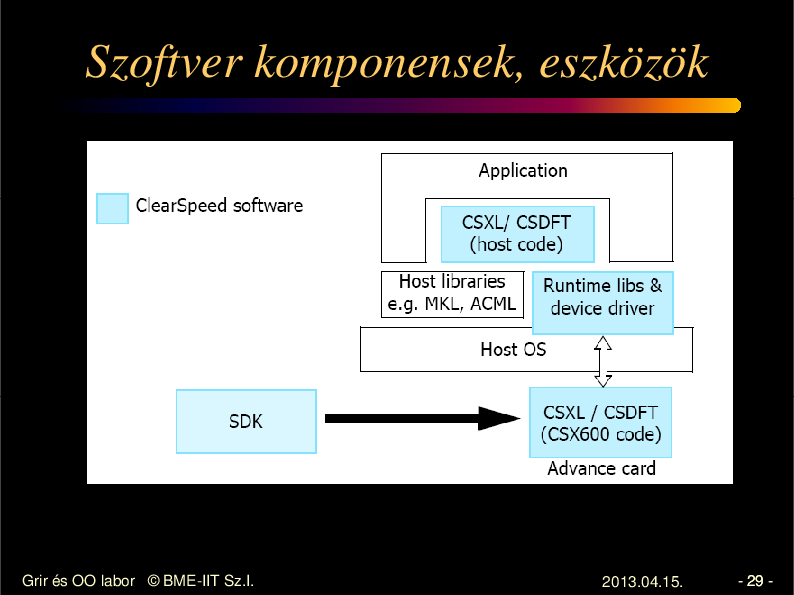
Szoftver komponensek, eszközök
• CSXL
– BLAS, LAPACK
• CSAPI
• SDK
–
–
–
–
–
Cn nyelv
Standard lib
Compiler (gcc)
Debugger (gdb)
Szimulator
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-7-
n
C
nyelv
• Standard ANSI C +
– 2 db új kulcsszó:
• poly
• mono
– Szabályok a két új tárolási osztály elérésére,
automatikus konverziójára.
• pointerek kezelési szabályai
• tömb, struct és union kezelési szabályai
• vezérlési szerkezetek speciális értelmezése
– Számos fv. a hw. kezelésére
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-8-

Egyszer példa
#include <stdio.h>
int main() {
printf("Hello world\n");
return 0;
}
Fordítás és futtatás:
cscn hello.cn –o hello.csx
csrun –r hello.csx
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
-9-

Kis módosítás
#include <stdiop.h>
int main() {
printfp("Hello world\n");
return 0;
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 10 -

mono és poly
poly int counter;
// minden PE-ben
mono double data;
// csak a mono unit-ban
float fix;
// ua. mint mono
// poly visszatérési érték függvény:
poly int fx(poly int, poly float);
// mono visszatérési érték függvény
mono int fx(poly int, poly int);
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 11 -

Újabb módosítás
#include <stdiop.h>
#include <lib_ext.h>
int main() {
poly int penum = get_penum();
printfp("Hello world %d\n",penum);
return 0;
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 12 -

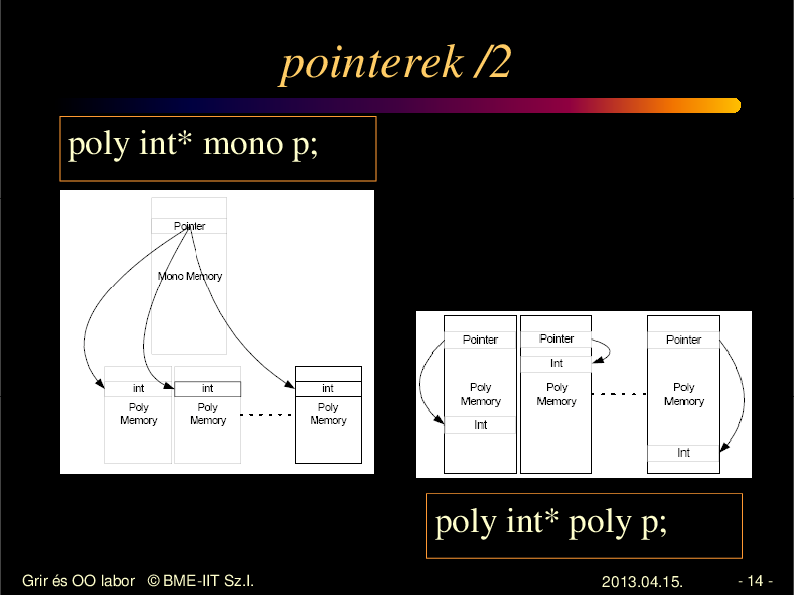
pointerek
mono int * mono p;
mono int * poly p;
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 13 -
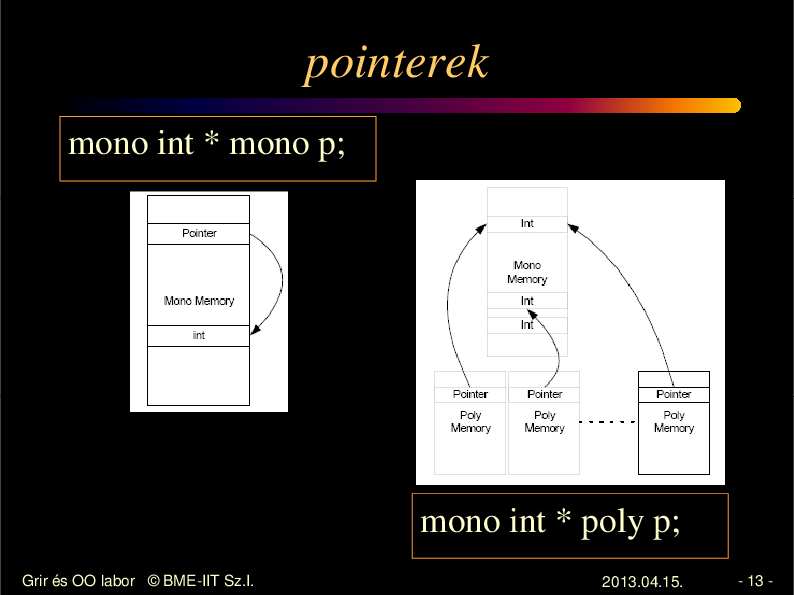
pointerek /2
poly int* mono p;
poly int* poly p;
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 14 -
struct és union
• A multiplicitást csak a típuson keresztül
lehet megadni.
struct str_t { int a; double d; };
mono struct str_t str1;
poly struct str_t str1;
• A typedef-fel is ugyanez a helyzet.
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 15 -

pointer cast és tömb
• nem lehet pointer multiplicitását
megváltoztatni cast-tal! Másik memória
terület!
• poly int tomb[100]
– poly int* mono tomb;
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 16 -

vegyes multiplicitás
mono a; poly b;
• mono változó mindig konvertálható polyvá. A konverzió automatikus.
b = a;
• Kifejezésben is lehet vegyesen, a kifejezés
értéke poly típusú lesz.
a+b
• Értelmetlen, és nem is lehet mono változóba
poly-t tenni.
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 17 -

vezérlési szerkezetek (if)
mono a; poly b;
if (a < 10) utas1 else utas2 // normál
if (b < 10) utas1 else utas2 // minden PE-ben
• Azok a PE-k melyekben a kif. nem teljesül
letiltódnak, majd az else végrehatásakor
azok tiltódnak, amelyekben teljesült.
• Végül mindkét ág végrehajtódik.
if (b < 1) a = 5; else a = 8; // mennyi a ??
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 18 -

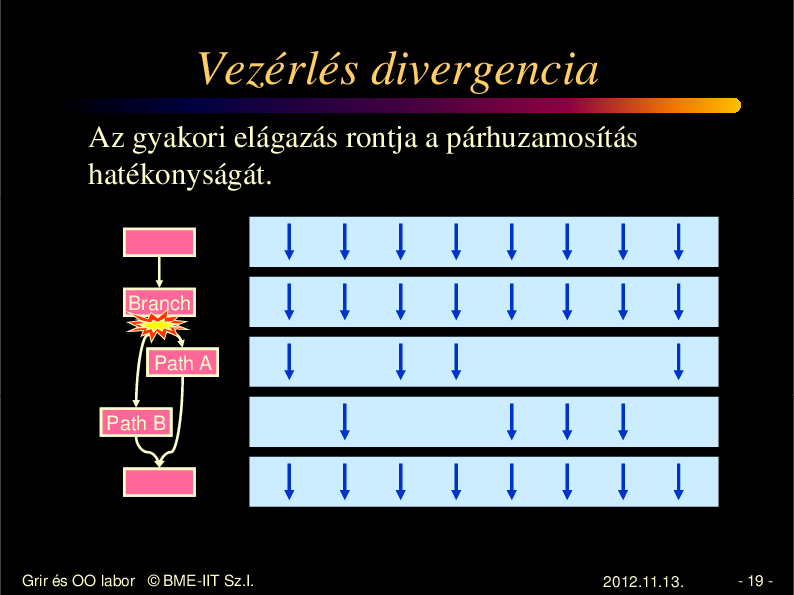
Vezérlés divergencia
Az gyakori elágazás rontja a párhuzamosítás
hatékonyságát.
Branch
Path A
Path B
Grir és OO labor © BME-IIT Sz.I.
2012.11.13.
- 19 -
for, while, do
mono a;
for (a = 0; a < 10; a++) utas // normál
poly b, i; // tfh., hogy i minden PE-ben más
for (b = 0; b < i; b++) utas // minden PE-ben
• Azok a PE-k melyekben a kif. nem teljesül
letiltódnak, a többiben fut a ciklus.
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 20 -

egyéb vezérlési szerkezet
• goto – nem léphet át poly kifejezésre
alapozott feltételt!
• helyette címkézett break és continue
használható:
for_i:
for (i=...) {
if (...)
break for_i;
}
• switch csak a mono vezérl ben futhat!
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 21 -

Adatmozgatás
• memcpym2p
• memcpyp2m
• memcpym2p_strided
• memcpyp2m_strided
Van aszinkron változatuk is.
Használatuk figyelmet igényel.
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 22 -

szemaforok
• értékük: nem negatív egész
• azonosítójuk: 0-92 (93-127: foglalt)
• m veletek:
–
–
–
–
–
sem_wait
sem_sig
sem_put
sem_get
sem_sync
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 23 -

1. példa: integrálás
double integ(double low, double high,
long n) {
double w, pew, sum; // mono-k
poly int penum;
// PE sorszám
poly double sump;
// PE részösszege
poly double l, h;
// határok
// PE sorszámának lekérdezése (0..95)
penum = get_penum();
w = (high-low)/n;
// lépésköz
pew = (high-low)/96;// PE-nkénti lépés
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 24 -

1. példa: integrálás / 2
l = pew*penum+low;
h = l + pew;
sump = 0.0;
l += w/2.0;
while (l < h) {
sump += fx(l);
l += w;
}
//
//
//
//
alsó határ
fels határ
téglányösszeg
fél lépéssel
// összegzés
// egész lépés
// minden PE sump-jét összeadja
sum = cs_reduce_sum(sump);
return sum * w;
// szorzás
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 25 -

1. példa: integrálás (PI)
#include
#include
#include
#include
<lib_ext.h>
<stdiop.h>
<stdlibp.h>
<reduction.h>
#define fx(x)
(4.0/(1.0+x*x))
#define N 1000000L
....
....
int main() {
printf("PI(%10ld): %15.13lf\n", N,
integ(0, 1, N));
return 0;
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 26 -

2. péda: rendezés cs vel
y0
x1
y1
x2
y2
x3
y3
x4
y4
x5
Minden feldolgozóra, minden lépésben:
xi = max(xi, yi-1), i = 1,2,3…n
yi = min(xi, yi-1), i = 1,2,3…n
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 27 -

2. péda: rendezés cs vel /2
unsigned int vec[NUM_PES];
int i, j;
poly int x, y, tmp; // PE-kben
x = y = -1;
// speciális érték
for (i = 0; i < NUM_PES; i++) {
set_swazzle_low(vec[i]); // új érték
y = swazzle_up(y); // belép + el z y
for (j = 0; j <= i; j++) { // i+1-szer
if (y > x) {
tmp = x; x = y; y = tmp;
}
y = circular_swazzle_up(y); // kisebb ->
}
} // x-ek nagyság szerint csökken en
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 28 -

Szoftver komponensek, eszközök
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 29 -
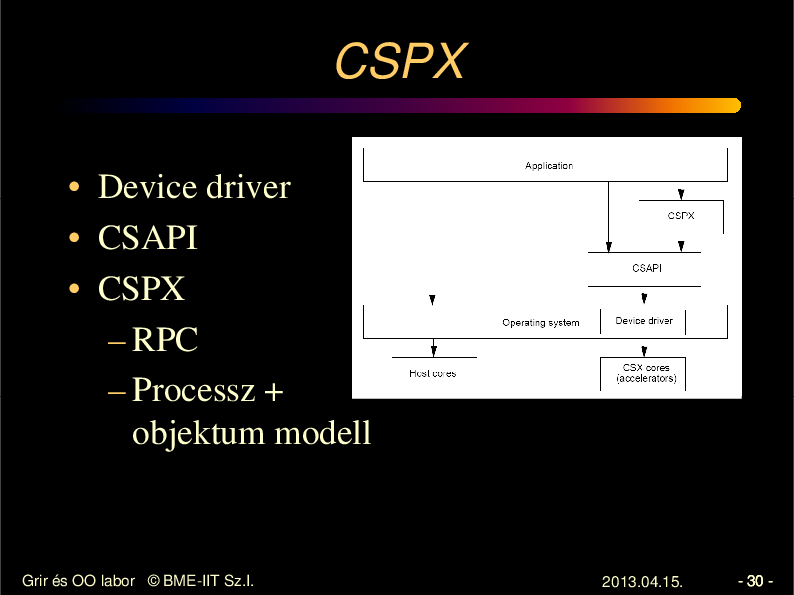
CSPX
• Device driver
• CSAPI
• CSPX
– RPC
– Processz +
objektum modell
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 30 -
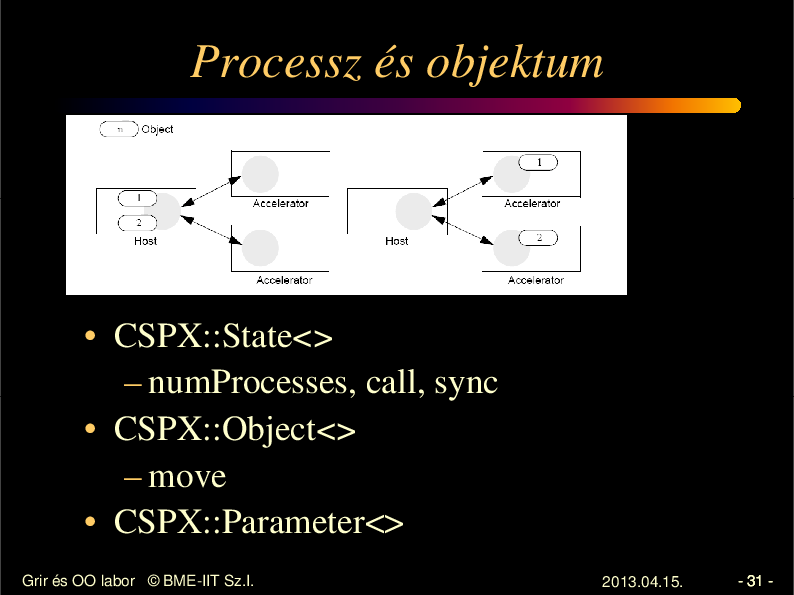
Processz és objektum
• CSPX::State<>
– numProcesses, call, sync
• CSPX::Object<>
– move
• CSPX::Parameter<>
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 31 -
Példa
• Vektor elemek négyzetgyöke
• Objektumok:
– input, output vektor
• Processzek:
– hoszt processz
– gyorsító kártyák processzei
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 32 -

Példa (cpp #1)
int main(void) {
static double inp[SIZE], res[SIZE];
CSPX::State<> processes("sqrt.csx");
int numProc = processes.numProcesses();// CPU-k
CSPX::Object<double> inputObj(inp, SIZE,
numProc, CSPX_OBJECT_WRITE);
CSPX::Object<double> resultObj(res, SIZE,
numProc, CSPX_OBJECT_READ);
.........
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 33 -

Példa (cpp #2)
int main(void) {
....
CSPX::Parameter pars(numProc);
pars.push(inputObj); // sorrend ua. mint a
pars.push(resultObj); // cn prog struktúrában
pars.push(SIZE/numProc);
for (int i = 0; i < SIZE; i++)
inp[i] = i*i;
processes.move(inputObj);
processes.move(resultObj);
....
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 34 -

Példa (cpp #3)
int main(void) {
....
processes.call(pars, "square_root"); // RPC!
processes.sync(resultObj);
for (int i=0; i < SIZE; i++) {
printf("%d: %.2f\n", i, res[i]);
}
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 35 -

Példa (cn #1)
struct sqrt_args {
// ebben a sorrendben
CSPXObject inputs;
// ment a pars.push
CSPXObject results;
int count;
};
#pragma cspx_export(square_root) // elérhet lesz
int square_root(CSPXProcess parent, void* pars) {
struct s_args *arg = (struct s_args *) pars;
double *inp, *res;
int i; CSPXErrno e;
CSPX_object_sync(&args->inputs); // átveszi
CSPX_object_sync(&args->results);
....
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 36 -

Példa (cn #2)
int square_root(CSPXProcess parent, void* pars)
...
inp = CSPX_object_get_pointer(&arg->inp, &e);
res = CSPX_object_get_pointer(&arg->res, &e);
for (i = 0; i < args->cnt; i += get_num_pes()){
poly double d;
poly int index;
index = i + get_penum();
memcpym2p(&d, &inp[index], sizeof(double));
d = sqrtp(d);
memcpyp2m(&res[index], &d, sizeof(double));
}
CSPX_object_move(parent, &args->results);
}
Grir és OO labor © BME-IIT Sz.I.
2013.04.15.
- 37 -
