Tipp: a diák között a J és K billentyűkkel lehet lépkedni.
Letöltés
Párhuzamos és Grid rendszerek
(1. ea)
alapfogalmak
Szeberényi Imre
BME IIT
<szebi@iit.bme.hu>
M
Párhuzamos és Grid rendszerek
© BME-IIT Sz.I.
EGYETEM 1782
2012.02.06.
-1-

Parallel programozás áttekintése
Miért fontos a párhuzamos feldolgozás ?
G
G
G
Nagyobb teljesítmény elérése miatt ? Csak a teljesítményért ?
G
a párhuzamosítás ebben az esetben csak technológia
G
nem fontos az alkalmazás tervez je számára
G
el kell fedni (mint pl. a hardware regisztereket, cache-t,...)
Egy lehetséges eszköz a valóság modellezésére
Egyszer sítheti a tervezési munkát
Párhuzamos feldolgozás problémái
G
G
G
G
G
Gyakran nehezebb kivitelezni, mint a soros feldolgozást
törékeny (nem determinisztikus viselkedés)
deadlock problémák léphetnek fel
er forrás allokációs problémák lehetnek
nem egyszer hibát keresni
Ezek valós tapasztalatok, de nem szükségszer ek!
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-2-

Történelmi áttekintés
• Neumann korában felmerült az ötlet (Daniel
Slotnick), de a csöves technológia nem tette
ezt lehet vé.
Els szupergép:
• 1967-ben ILLIAC IV (256 proc, 200MFlop)
• Thinking Machines CM-1, CM-2 (1980)
• Cray-1
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-3-

Jellemz szupersz.gép típusok
• Vektorprocesszoros rendszerek
– Gyors m veletvégzés vektor jelleg adatokon
• Masszívan párhuzamos rendszerek (MPP)
– Üzenetküldéses elosztott memóriás (MDM)
– Szimmetrikus multiprocesszoros (SMP)
– Elosztott közös memória (DSM)
• Elosztott számítási rendszerek
– Homogén rendszerek
– Heterogén rendszerek
• Metaszámítógépek és Grid redszerek
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-4-

Párhuzamos gép modellje
• Több modell alakult ki.
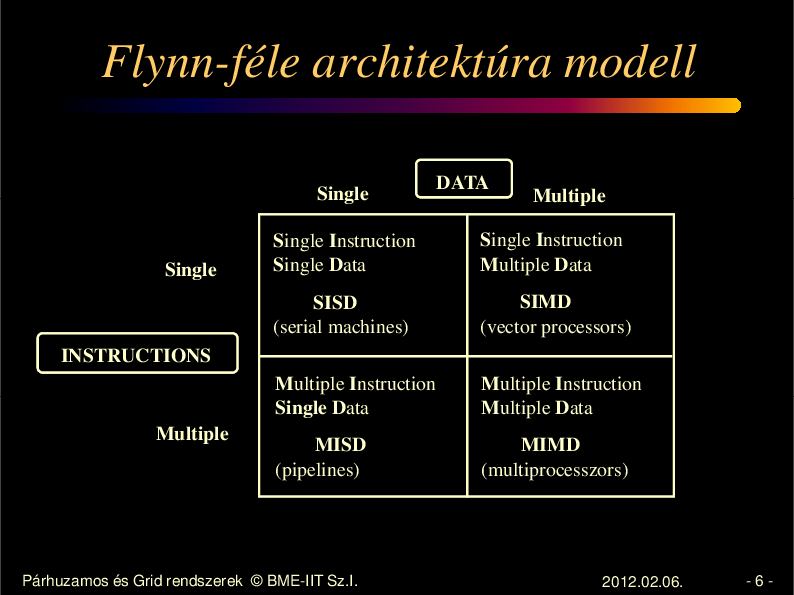
• A legegyszer bb a Flynn-féle modell, mely
a Neumann modell kiterjesztésének tekinti a
párhuzamos gépet.
• A másik gyakran alkalmazott modell az
idealizált párhuzamos számítógép modell
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-5-

Flynn-féle architektúra modell
Single
DATA
Multiple
Single Instruction
Multiple Data
SISD
(serial machines)
SIMD
(vector processors)
Multiple Instruction
Single D
Data
Single
Single Instruction
Single Data
Multiple Instruction
Multiple D
M
Data
MISD
(pipelines)
MIMD
(multiprocesszors)
INSTRUCTIONS
Multiple
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-6-
Idealizált párhuzamos számítógép
memória
memória
memória
CPU 1
CPU 2
CPU 3
Összeköttetés
G
G
Több processzor egyazon problémán dolgozik.
Minden processzornak saját memóriája és
címtartománya van.
G
Üzenetekkel koordinálnak és adatokat is tudnak átadni.
G
A lokális memória elérése gyorsabb.
G
Az átviteli sebesség független a csatorna forgalmától.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-7-

Architektúrák jellemz i
G
Processzorok eloszlása
G
Homogén vagy heterogén
G
A kapcsolat késleltetése és sávszélessége
G
Topológia
Hálók
Gy r k
Fák
Hiperkockák
Teljesen összekötött
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-8-

Programozási modell
• Közös memóriás
• Elosztott közös memóriás
• Üzenet küldéses
Valójában egyik modell sem köt dik
szorosan a tényleges architektúrához
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
-9-

Közös memória elv jellemz i
Közös memória használatának el nyei
Egységes hozzáférés
G
Egyszer bb programozás
G
A hw adottságaitól függ en jó speed-up értékel érhet k el
Közös memória használatának hátrányai
G
G
G
G
G
Memória-hozzáférés sz k keresztmetszetet jelenthet
Nem jól skálázható
Cache problémák megoldása külön hardvert igényel
Nehéz nyomkövethet ség
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 10 -

Elosztott memória elv jellemz i
Elosztott memória használatának el nyei
G
G
G
G
Skálázható
Költségkímél
A redundancia növelésével növekedhet a megbizhatóság
Speciális feldolgozó eszközökkel is együttm ködik
Elosztott memória használatának hátrányai
G
G
G
G
G
Kommunikáció igényes
Nem minden algoritmus párhuzamosítható így
A meglev soros programokat és a közös memóriát használó
alkalmazásokat át kell dolgozni
Jó speed up értékeket nehéz elérni
Nehéz nyomkövethet ség
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 11 -

Párhuzamos gépek osztályai
• Szimmetrikus multiprocesszoros (SMP)
– sok azonos processzor közös memóriával
– egy operációs rendszerrel
– NUMA, ccNUMA
• Masszívan párhuzamos (MPP)
– sok processzor gyors bels hálózattal
– elosztott memória
– sok példányban fut az operációs rendszer
• Klaszter
– sok gép gyors hálózattal összekötve
– elosztott memória
– sok példányban esetleg heterogén operációs rendszer
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 12 -

Teljesítménymérés
Sebességnövekedés (Speed Up):
Sn = Ts/Tn
ahol:Sn N processzorral elért sebességnövekedés
Ts futási id soros végrehajtás esetén
Tn futási id N processzor esetén
Hatékonyság (Efficiency):
En = Sn/N
ahol:En N processzorral elért hatékonyság
Sn N processzorral elért sebességnövekedés
N processzorok száma
Rededundancia (Redundancy):
r = Cp/Cs
ahol:r
párhuzamos program redundanciája
Cp párhuzamos program m veleteinek száma
Cs soros program m veleteinek száma
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 13 -

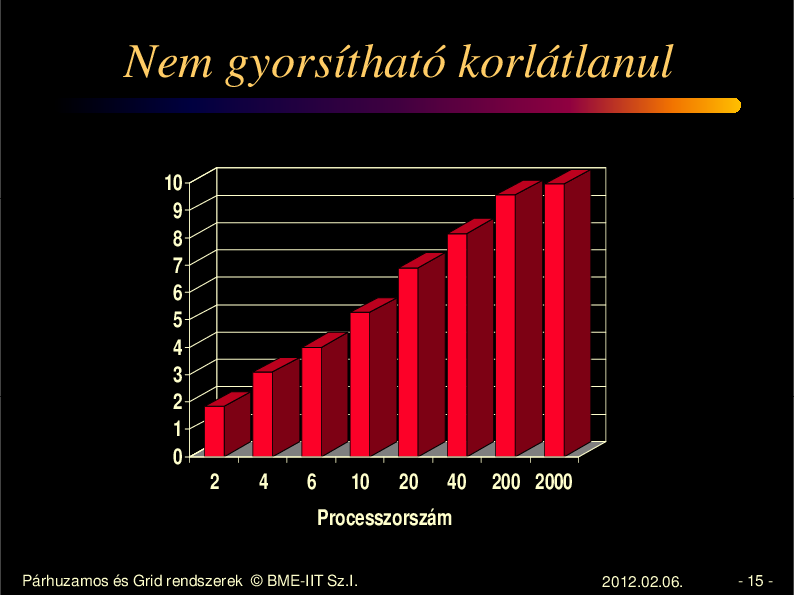
Speed Up határa
Amdahl féle fels határ:
Sa = 1/(s+(1-s)/N)
ahol:Sa N processzorral elértetô sebességnövekedés felsô
határa
s a feladat nem párhuzamosítható része
N processzorok száma
Az (1-s)/N tagot elhagyva:
Sa < 1/s
összefüggést kapjuk, ami egy fels korlátot ad. Ez azt jelenti,
hogy pl. 10% nem párhuzamosítható rész mellet 1/0.1 = 10
adódik a speed up fels korlátjaként.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 14 -

Nem gyorsítható korlátlanul
10
9
8
7
6
5
4
3
2
1
0
2
4
6
10
20
40
200 2000
Processzorszám
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 15 -
Programozási nyelvek
• Linda – közös memória modell, Tuple Space
–
–
–
–
out – kimásol egy adathalmazt a közös területre
in, inp – behoz egy adathalmazt (megsz nik)
rd, rdp – behoz egy adathalmazt
eval – végrehajt egy függvényt processzként
Egyszer modell, de implementációs nehézségek vannak,
f leg az üzenetküldéses architektúrákon.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 16 -

Programozási nyelvek/2
• Express – elosztott memória modell
160 C-b l és fortranból hívható rutin:
– programindítás, leállítás
– logikai kommunikációs topológia felépítése
– programok közötti kommunikáció,
szinkronizáció
– fájlm veletek
– grafikai m veletek
– teljesítmény analízis, debug
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 17 -

Programozási nyelvek/3
• PVM – elosztott memória modell
70 C-b l és fortranból hívható rutin:
– programindítás, leállítás
– programok közötti kommunikáció,
szinkronizáció
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 18 -

Mire használják a PVM-et ?
G
"Szegények" szuperkomputere
a szabad CPU kapacitások összegy jthet k a
munkaállomásokról és a PC-r l
G
G
Több szuperkomputer összekapcsolásával hihetetlen számítási
kapacitás állítható el
Oktatási eszköz
a párhuzamos programozás tanításához hatékony eszköz
G
Kutatási eszköz
skálázható és költségkímél
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 19 -

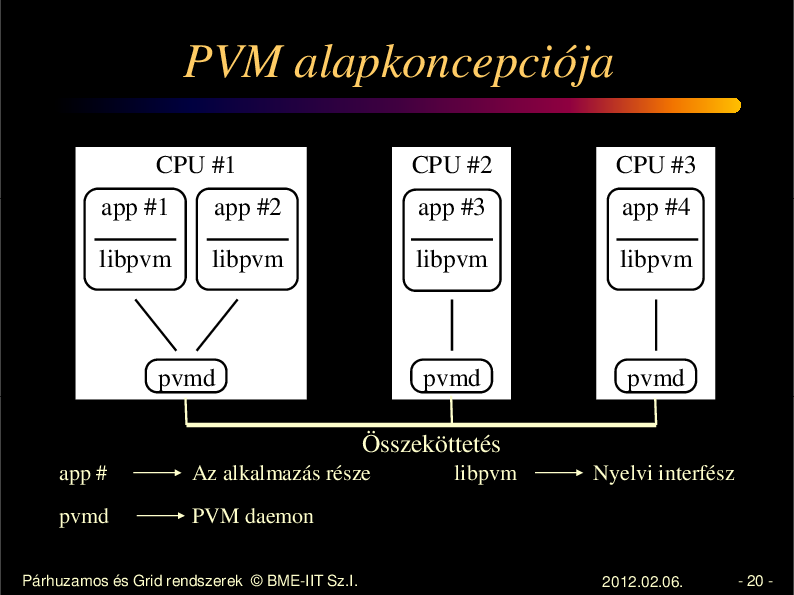
PVM alapkoncepciója
CPU #1
CPU #2
CPU #3
app #1
app #2
app #3
app #4
libpvm
libpvm
libpvm
libpvm
pvmd
pvmd
pvmd
Összeköttetés
app #
Az alkalmazás része
pvmd
PVM daemon
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
libpvm
Nyelvi interfész
2012.02.06.
- 20 -
libpvm
A libpvm által nyújtott funkciók a négy csoportra oszthatók:
• Adminisztratív funkciók
Virtuális gép indítása, megállítása, álapotlekérdezés, új
node felvétele
• Folyamatkezel funkciók
Folyamatok indítása, megállítása
• Adatátviteli funkciók
Üzenetek összeállítása, elküldése, vétele, szétcsomagolás
• Szinkronizációs funkciók
Üzenetküldéssel, vagy barrier használatával
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 21 -

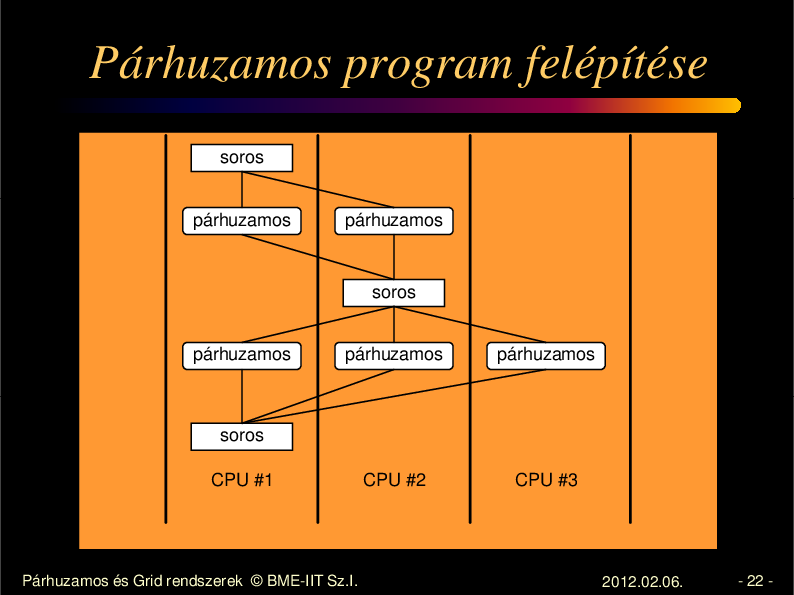
Párhuzamos program felépítése
soros
párhuzamos
párhuzamos
soros
párhuzamos
párhuzamos
párhuzamos
CPU #2
CPU #3
soros
CPU #1
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 22 -
Párhuzamosítási startégiák
Kényszer
G A program soros változatát futtatjuk párhuzamosan
különböz adatokkal.
G Csak akkor kielégít módszer, ha a soros változat
elviselhet futási idej .
Ciklusok párhuzamosítása
G Akkor alkalmazható, ha az egyes iterációk függetlenek
egymástól
Felosztó párhuzamosítás (master / slave)
G Egy felügyel taszk fut az egyik node-on
G Akkor alkalmazható, ha a felügyel program feladatai
egyszer bbek mint a többi taszk feladatai.
G Ha a taszkok függetlenek egymástól, akkor jól skálázható
a taszkok számának változtatásával.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 23 -

Párhuzamosítási startégiák /2
Egymást követ
G Minden node a következ node-nak adja tovább a részben
feldolgozott adatot.
G Akkor használható, ha a soros része a feldolgozásnak
lényegesen rövidebb, mint a párhuzamos rész.
G Rendszerint minden node azonos kódot futtat.
G Különösen alkalmas a gy r topológiához.
Régiók párhuzamosítása
G Az adatfügg ség régiókba lokalizálható.
G Akkor használható, soros végrehajtási id nagyobb mint a
párhuzamos.
G Rendszerint nagy kommunikációigény .
G Legbonyolultabb.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 24 -

Párhuzamosítási példa
Számítsuk ki az
integrál értékét egyszer numerikus
közelítéssel (téglány összegek)!
B
∫ f ( x) dx
A
N=8 esetén pl:
B
B-A
ahol h=
N
N
h
∫ f (x) dx = h⋅ ∑f (A− 2 +i ⋅ h)
i=1
A
f(x)
t1 t2 t3
A
h
t4
t5 t6
t7 t8
B
x
Az egyes téglányok számítása egymástól függetlenül, párhuzamosan is elvégezhet .
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 25 -

Párhuzamosítási példa
Számítsuk ki az
integrál értékét egyszer numerikus
közelítéssel (téglány összegek)!
B
∫ f ( x) dx
A
N=8 esetén pl:
B
B-A
ahol h=
N
N
h
∫ f (x) dx = h⋅ ∑f (A− 2 +i ⋅ h)
i=1
A
P1
f(x)
t1 t2 t3
A
h
t4
t5 t6
t7 t8
B
x
Az egyes téglányok számítása egymástól függetlenül, párhuzamosan is elvégezhet .
Pl. minden task csak minden M-edik téglányt számol ki, majd az összegezzük az
eredményeket.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 26 -

Párhuzamosítási példa
Számítsuk ki az
integrál értékét egyszer numerikus
közelítéssel (téglány összegek)!
B
∫ f ( x) dx
A
N=8 esetén pl:
B
B-A
ahol h=
N
N
h
∫ f (x) dx = h⋅ ∑f (A− 2 +i ⋅ h)
i=1
A
P1
f(x)
P2
t1 t2 t3
A
h
t4
t5 t6
t7 t8
B
x
Az egyes téglányok számítása egymástól függetlenül, párhuzamosan is elvégezhet .
Pl. minden task csak minden M-edik téglányt számol ki, majd az összegezzük az
eredményeket.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 27 -

Párhuzamosítási példa
Számítsuk ki az
integrál értékét egyszer numerikus
közelítéssel (téglány összegek)!
B
∫ f ( x) dx
A
N=8 esetén pl:
B
B-A
ahol h=
N
N
h
∫ f (x) dx = h⋅ ∑f (A− 2 +i ⋅ h)
i=1
A
P1
f(x)
P2
t1 t2 t3
A
h
t4
t5 t6
P3
t7 t8
B
x
Az egyes téglányok számítása egymástól függetlenül, párhuzamosan is elvégezhet .
Pl. minden task csak minden M-edik téglányt számol ki, majd az összegezzük az
eredményeket.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 28 -

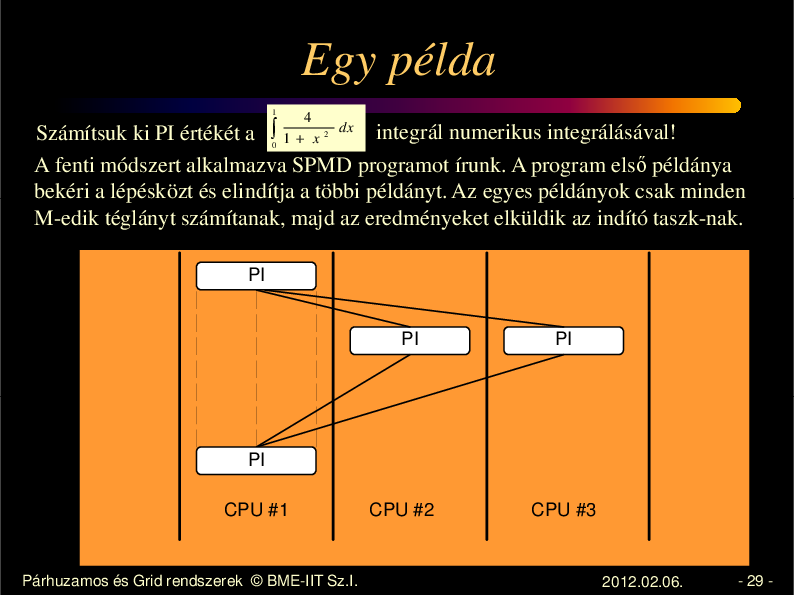
Egy példa
1
4
1+ x
dx
integrál numerikus integrálásával!
Számítsuk ki PI értékét a ∫
A fenti módszert alkalmazva SPMD programot írunk. A program els példánya
bekéri a lépésközt és elindítja a többi példányt. Az egyes példányok csak minden
M-edik téglányt számítanak, majd az eredményeket elküldik az indító taszk-nak.
0
2
PI
PI
PI
PI
CPU #1
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
CPU #2
CPU #3
2012.02.06.
- 29 -
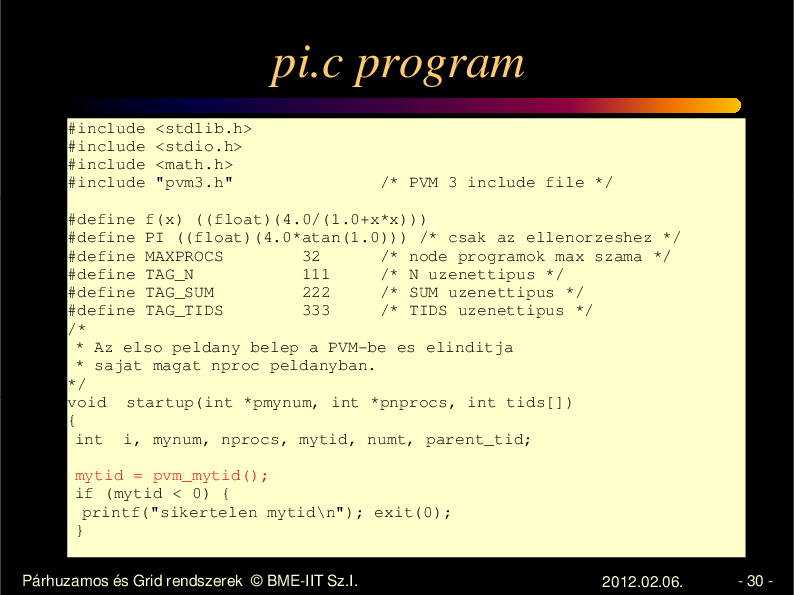
pi.c program
#include
#include
#include
#include
<stdlib.h>
<stdio.h>
<math.h>
"pvm3.h"
/* PVM 3 include file */
#define f(x) ((float)(4.0/(1.0+x*x)))
#define PI ((float)(4.0*atan(1.0))) /* csak az ellenorzeshez */
#define MAXPROCS
32
/* node programok max szama */
#define TAG_N
111
/* N uzenettipus */
#define TAG_SUM
222
/* SUM uzenettipus */
#define TAG_TIDS
333
/* TIDS uzenettipus */
/*
* Az elso peldany belep a PVM-be es elinditja
* sajat magat nproc peldanyban.
*/
void startup(int *pmynum, int *pnprocs, int tids[])
{
int i, mynum, nprocs, mytid, numt, parent_tid;
mytid = pvm_mytid();
if (mytid < 0) {
printf("sikertelen mytid\n"); exit(0);
}
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 30 -
pi.c program /2
parent_tid = pvm_parent();
if (parent_tid == PvmNoParent) { /* ez az elso peldany */
mynum = 0; tids[0] = mytid;
printf ("Hany node peldany(1-%d)?\n", MAXPROCS);
scanf("%d", nprocs);
numt = pvm_spawn("pi", NULL, PvmTaskDefault, "", nprocs, &tids[1]);
if (numt != nprocs) {
printf ("Hibas taszk inditas numt= %d\n",numt); exit(0);
}
*pnprocs = nprocs;
/* node peldanyok szama */
pvm_initsend(PvmDataDefault);
/* tid info az mindenkinek */
pvm_pkint(&nprocs, 1, 1);
pvm_pkint(tids, nprocs+1, 1);
pvm_mcast(&tids[1], nprocs, TAG_TIDS);
} else {
/* ez nem elso peldany */
pvm_recv(parent_tid, TAG_TIDS);
pvm_upkint(&nprocs, 1, 1);
pvm_upkint(tids, nprocs+1, 1);
for (i = 1; i <= nprocs; i++)
if (mytid == tids[i]) mynum=i;
}
*pmynum = mynum;
}
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 31 -

pi.c program /3
/*
* N ertek eloallitasa. (Az elso peldany bekeri).
*/
void solicit(int *pN, int *pnprocs, int mynum, int tids[])
{
if (mynum == 0) {
/* ez az elso taszk */
printf("Kozelites lepesszama:(0 = vege)\n");
if (scanf("%d", pN) != 1) *pN = 0;
pvm_initsend(PvmDataDefault);
pvm_pkint(pN,1,1);
pvm_pkint(pnprocs,1,1);
pvm_mcast(&tids[1], *pnprocs, TAG_N);
} else {
/* egyebkent a fonok node kuldi */
pvm_recv(tids[0], TAG_N);
pvm_upkint(pN, 1, 1);
pvm_upkint(pnprocs, 1, 1);
}
}
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 32 -

pi.c program /4
main()
{
float sum, w, x;
int
i, N, M, mynum, nprocs, tids[MAXPROCS+1];
startup(&mynum, &nprocs, tids);
for (;;) {
solicit (&N, &nprocs, mynum, tids);
if (N <= 0) {
printf("A %d. peldany kilep a virtualis gepbol\n", mynum);
pvm_exit(); exit(0);
}
}
/*
* Szamitas. M=nprocs+1 peldany van, igy csak minden M.
* teglanyt szamolja egy processz. */
M = nprocs+1;
w = 1.0/(float)N;
sum = 0.0;
for (i = mynum+1; i <= N; i += M)
sum = sum + f(((float)i-0.5)*w);
sum = sum * w;
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 33 -

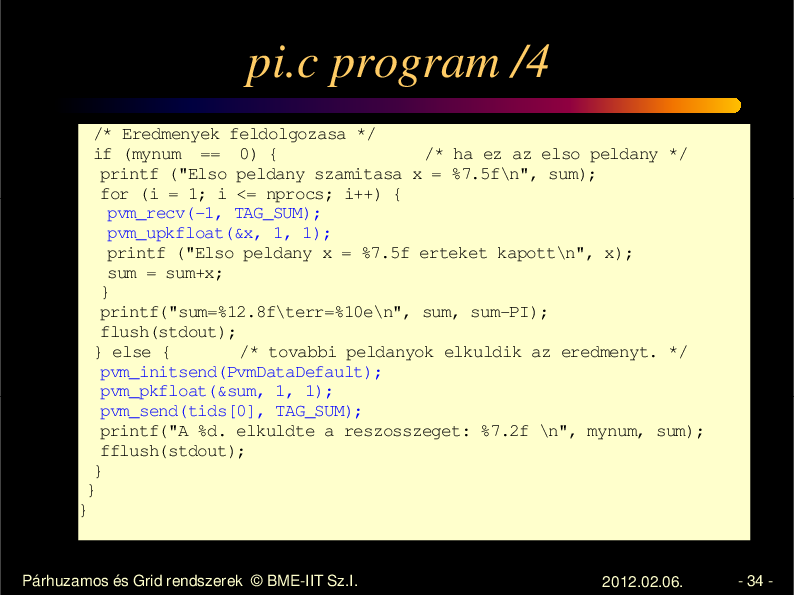
pi.c program /4
/* Eredmenyek feldolgozasa */
if (mynum == 0) {
/* ha ez az elso peldany */
printf ("Elso peldany szamitasa x = %7.5f\n", sum);
for (i = 1; i <= nprocs; i++) {
pvm_recv(-1, TAG_SUM);
pvm_upkfloat(&x, 1, 1);
printf ("Elso peldany x = %7.5f erteket kapott\n", x);
sum = sum+x;
}
printf("sum=%12.8f\terr=%10e\n", sum, sum-PI);
flush(stdout);
} else {
/* tovabbi peldanyok elkuldik az eredmenyt. */
pvm_initsend(PvmDataDefault);
pvm_pkfloat(&sum, 1, 1);
pvm_send(tids[0], TAG_SUM);
printf("A %d. elkuldte a reszosszeget: %7.2f \n", mynum, sum);
fflush(stdout);
}
}
}
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 34 -
Message Passing Interface (MPI)
• Alapvet en más célokkal fejl dött ki:
– szabványos, a gyártók által elfogadott, speciális
hw. környezetet is támogató fejl. környezet.
– hosszú ny gös fejl dés
– kezdetben csak statikus processzkezelés
– nem igényli a virtuális gép el zetes felépítését,
mert a teljes kommunikációs séma az
alkalmazáshoz szerkeszt dik.
– Ezzel szemben a PVM op.r. funkciókat nyújt.
viszonylag gyorsan fejlesztették.
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 35 -

Cluster koncepció
•
•
•
•
Gyors hálózattal összekapcsolt gépek
Gyakran közös fájlrendszer
CPU vagy tárolási kapacitás növelése
Paraméter study, vagy párhuzamos
alkalmazások
Párhuzamos és Grid rendszerek © BME-IIT Sz.I.
2012.02.06.
- 36 -
